<執筆論文紹介>犬の僧帽弁修復術の術後30日全原因死亡の予測モデルに関する研究
僧帽弁修復術(MVR)を受けた犬2089頭のデータを用いた術後30日死亡リスク予測モデルに関する論文がJournal of Veterinary Internal Medicineに掲載されました。
Furusato, S. et al. Preoperative Prediction Models for 30-Day All-Cause Mortality After Mitral Valve Repair in Dogs: A Single-Center Retrospective Cohort Study. J. Vet. Intern. Med. 39, (2025). https://onlinelibrary.wiley.com/doi/10.1111/jvim.70152
MVRは粘液腫様変性性僧帽弁疾患(MMVD)に対する有望な外科的治療手段ですが、侵襲性の高い開心術であり、術後早期の死亡リスクは無視できません。 治療の実施是非は、その手術がもたらすメリットとデメリットのバランスを考慮して判断する必要があります。 しかしながら、術前にMVRの術後早期の死亡リスクを定量的に評価する手段は存在しませんでした。
今回我々は、当センターで2016~2023年にMVRを実施したMMVD犬2089頭の電子カルテデータを活用して、術前の患者シグナルメント、麻酔前検査(血液検査、画像検査指標)、術前投薬内容からMVRの術後30日全原因死亡を予測する統計モデルを構築し、その性能を評価しました。
研究のポイント:
- MVR後30日以内の死亡率は4.9%
- 術前のビリルビン、総蛋白、VHS、LA/Ao、APTTが主要な予測因子
- 術後早期の死亡予測確率は、術後2年間の長期予後とも関連することが示され、術後早期死亡リスクが高い患者集団は、急性期を乗り越えたあとでも依然として慎重なモニタリングが必要であることを示唆
- 予測モデルをWebアプリに実装
単施設の回顧的研究であることが最大のリミテーションであり、開発した予測モデルの他施設での予測性能はまだ未知数です。今後は多施設共同での外的検証を進めていきたいと思います。
ーーーーーー
予測モデル研究は独学でしたが、無事に成果が出てよかったです。 SteyerbergのClinical prediction model、HarrellのRegression Modeling Strategiesなどの教科書と、TRIPOD statement、予測モデルの解説論文や原著/総説論文がとても参考になりました。(勉強内容の一部はこのブログでも過去に何度かまとめました)
<執筆論文紹介>非腫瘍性T細胞による自己免疫異常所見を示唆する病理所見を得た犬の慢性肝炎の一例: Case report
前職で執筆していたCase reportがアクセプトされ3月初旬にVeterinary Scienceに出版されました
A Case of Canine Hepatitis with Hepatocellular Attack by Non-Neoplastic Perforin-Laden Lymphocytes
- 犬の特発性慢性肝炎は機序の一つに免疫介在性の存在が示唆されているものの、未だ明確な診断基準が定まっていません
- 本論文は、慢性的な肝酵素上昇を認めた犬の病理検査より、CD-3陽性パフォーリン陽性T細胞による肝細胞攻撃所見を認め、自己免疫介在性肝炎として免疫抑制治療を行った症例について報告しています
- 人では自己免疫性肝炎(AIH)が肝炎の一つとして存在し、病理学的な診断基準も確立しています。今回の犬の病理組織像とAIHの類似性、相違性についても考察しています
- 本報告が犬の免疫介在性肝炎の診断標準化の一助になることを期待しています。
p-value、信頼区間の考え方と、より良い統計的結果の解釈の仕方について ~Weng H et al., JVIM, 2024の論文を例に~
獣医学
Weng, H. & Messam, L. L. McV. Reporting and interpreting statistical results in veterinary medicine: Calling for change. J. Vet. Intern. Med. (2024) doi:10.1111/jvim.17258.
introduction
根拠に基づいた獣医療(EBVM)の重要性は増している
EBVMの実践に必要なスキルの一つは、科学論文の統計的な解析結果を正しく解釈して、臨床上の意思決定 に応用すること
しかし、獣医学論文の多くは、統計的有意差にのみ基づいて研究結果が結論付けられてしまっており、 EBVMの実践と乖離がある
米国統計協会(ASA)は、2016年に統計的有意性の限界点について声明を出した
日本語翻訳版→ https://www.biometrics.gr.jp/news/all/ASA.pdf
誤解 (1) p-valueは効果の大きさの指標ではない(統計的有意性≠臨床的重要性)
誤解 (3) p-valueはエビデンスの程度を示す指標ではない (統計的に有意だからといってエビデンスが強い訳では無い)
ASA声明から9年ほど経過するが、獣医学論文でのp-valueの誤った使い方は未だに蔓延している
目的:獣医学関係者に対して、統計的な結果のより良い報告の仕方、解釈の仕方を提供すること
仮想的なランダム化比較試験
目的:腎臓療法食がCKDの進行を抑制するか?
P: CKD stage2の猫
I: 腎臓療法食A, B, C, D
C: Control食
O: CKD stage2診断から1年後の体重変化率
腎臓療法食を与えることで、Control食に比べて CKDの進行(=体重減少)を抑えられるか検証
p-valueのざっくりとした定義
a p-value is the probability under a specified statistical model that a statistical summary of the data (e.g., the sample mean difference between two compared groups) would be equal to or more extreme than its observed value. (Wasserstein et al., The American Statistician, 2016)
和訳: “p-valueとは、特定の統計モデルの下でデータの統計的要約(標本平均の差など)が、実際に観測された値 と同じかそれ以上に極端な値を取る確率のこと”
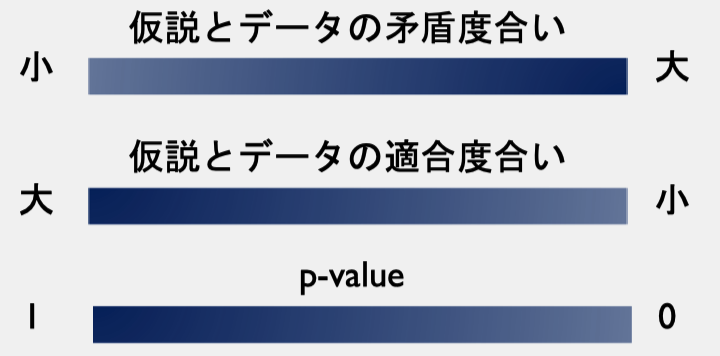
p-valueは、特定の統計モデル(仮説)とデータが⽭盾する程度を⽰す指標の⼀つ
⾔い換えると、p-valueは、特定の統計モデル(仮説)とデータの適合度の指標の⼀つ
仮説検定の場合、帰無仮説が特定の統計モデルに該当し、実際の観測結果がデータに該当する
仮想的なRCTを用いてp-valueを再考する
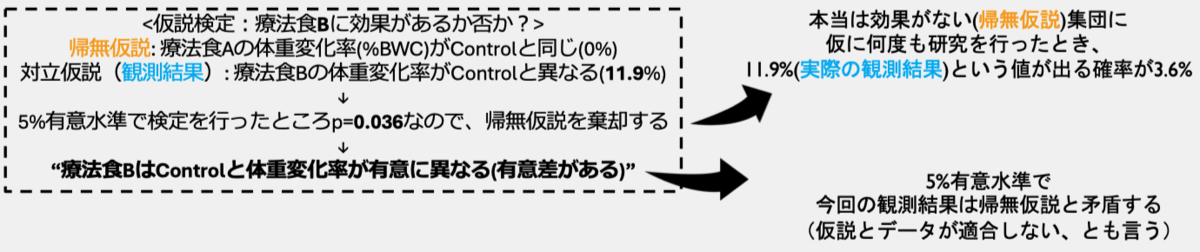
p値関数(信頼区間関数)
- 帰無仮説だけでなく、あらゆる値(仮説)に対して同様にp-valueを計算することができる
- ”療法⾷Aと Controlの体重変化率の差が5.3%”という仮説を考えると、その仮説と今回の観測結果(5.3%)は “全く⽭盾しない” = “完璧に適合する” = "p=1”
- そのようにして、今回の観測結果と様々な仮説の⽭盾度合い(適合度合い=p-value)をプロットしていくと…結果の取りうる範囲のあらゆる仮説に対するp-valueの曲線が描ける=p値関数
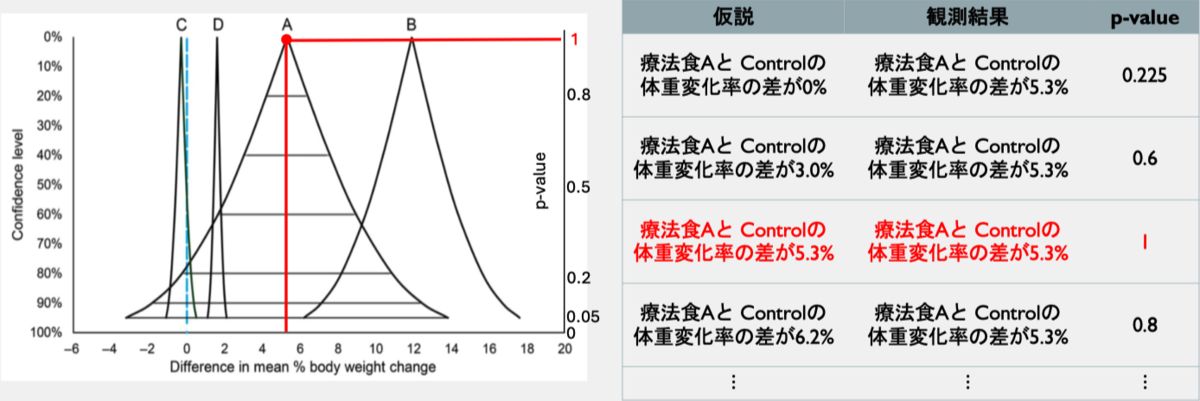
95%信頼区間(CI)
95%CIとは、ある仮説に対して、観測結果が5%有意⽔準で仮説検定を棄却できない領域 (p>0.05で観測結果と⽭盾しない or 適合する仮説の集合)
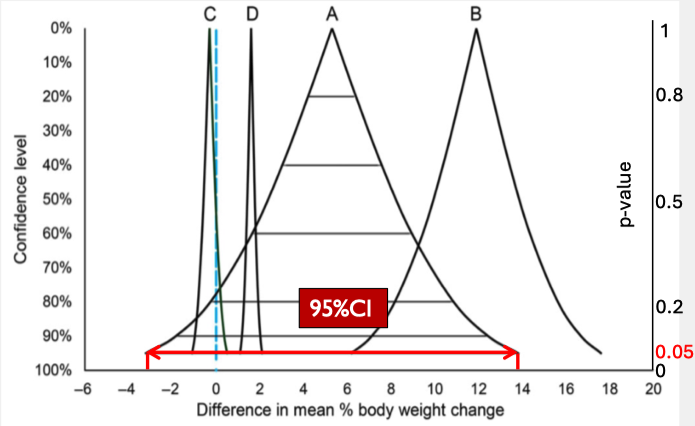
p値関数を用いた実践的な結果の解釈の仕方
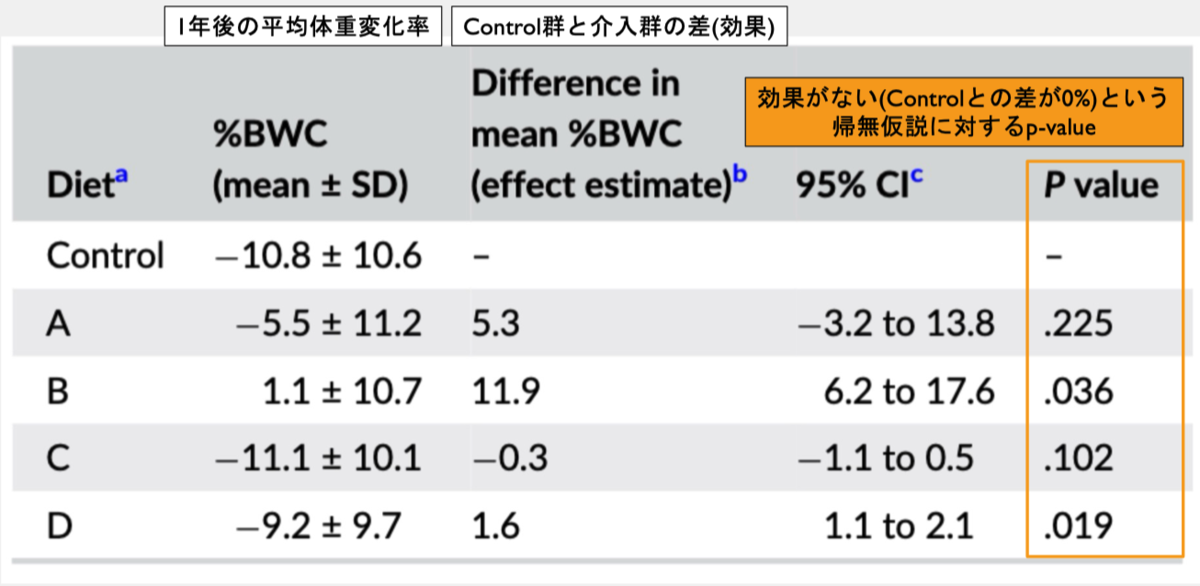
p値だけでみると…最もp値が小さいのは療法食D (p=0.019)であり、p値関数の分布を見ても、データに適合する値の領域は狭く(95%CI: 1.1~2.1)、推定の精度は高い(推定の不確実性が低い)が、効果量自体は大きくない
療法食Bはp=0.036だが、データが最も適合する効果量は11.9と効果量が大きい。p値関数の分布は広く、推定の不確実性自体は療法食Dに比べて大きいが、それでも最もデータとの適合度が低い95%CI下限値でさえ6.2と大きな効果量を持つ。したがって、このStudyにおいて、Controlや他の療法食に比べて療法食Bは相対的に大きな体重減少抑制効果があると言える。
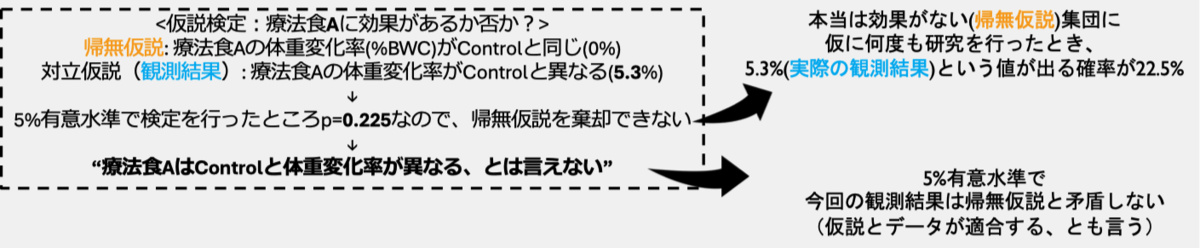
- 療法食Aはp=0.225であり、帰無仮説に対する仮説検定を行うと有意差がないという判定になる。しかしデータに最も適合する値(点推定値)は5.3、95%CIの上限は13.8であり、p値関数の分布の大半が体重減少抑制効果がある方向に推定されている。したがって療法食AはControlより体重減少抑制効果があるという推定は大雑把に矛盾しておらず、更にその大半の推定効果量も療法食Dに比べて大きい。しかし、Controlよりも体重減少率が3.2%悪化するという推定を否定はできず、Controlのほうが療法食Aより優れているという結論に対して、この推定結果では合理的に否定する根拠はないように見える
まとめ
研究結果の臨床的重要性をp-valueや統計的有意性に基づいて決めるべきではない!
- p-valueは臨床的重要性を示すものではない
- p-valueは結果の精度(再現性)の高さを示すものではない
- p-valueはエビデンスの強さを示すものではない
- 統計的有意性のような二値的な判断ではなく、95%CIやp値関数を用いて連続的に効果の程度、推定の精度、臨床的重要性を議論する事が重要
Advance: 特定の統計モデルとはなにか
“p-valueとは、特定の統計モデルの下でデータの統計的要約(標本平均の差など)が、実際に観測された値と同じかそれ以上に極端な値を取る確率のこと”
p-valueは、特定の統計モデル(仮説)とデータが矛盾する程度を示す指標の一つ
言い換えると、p-valueは、特定の統計モデル(仮説)とデータの適合度の指標の一つ
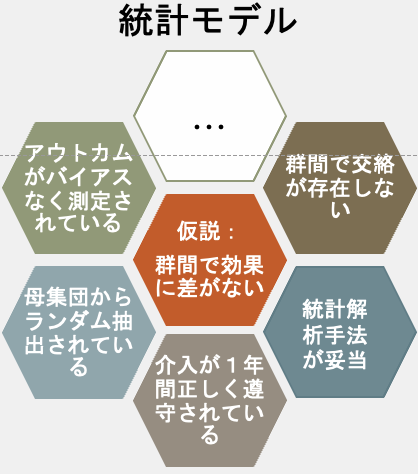
- ”特定の統計モデル”には、仮説だけでなく、RCTが実施される工程、データ(アウトカム)が取得される工程、データから統計解析(検定)を行う工程などのすべてが含まれている
- 特定の統計モデルとデータ(観測結果)のpが小さい時、統計モデルとデータのどこかが矛盾している、ということになる
- 仮説がデータと矛盾しているのかもしれないし、仮説以外の統計モデルの構成要素のどれかが矛盾しているのかもしれない
- しかし、p-valueだけでは、統計モデルとデータのどこが矛盾しているのかわからない
- 統計モデルを構成する”仮説”が妥当か否かを評価するためには、研究デザイン、データ取得工程などを総合的に評価する必要がある
- なので、p-valueだけでは仮説が正しいかどうかの指標にはならないし、仮説が正しいもとで偶然によってデータが得られる確率がp-valueというわけでもない
- 結局は仮説の妥当性を評価するには研究全体を吟味する必要がある
Causal inference- What if chapter3勉強まとめ; Consistencyについて
最近忙しかったりなんやかんやで更新が滞っていましたが、コツコツ進んでいます。 因果推論のほうはCausal inference- what ifをchapter4まで読みました。
chapter3 observational studyを読んだなかでは、因果効果の識別三条件のうちconsistencyの理解が最も難しかったですが、自分の中でコレだ!という的を得たので、まとめていきます。
まずこの本では、治療介入Aを確率変数A、実現値aで表していますが、その使い分けを理解するのが難しい。
一見すると、反実仮想アウトカムにおける介入はa、観測アウトカムにおける介入はAで表されているように見えますが、そうではないということがポイントでした。
Chapter 1で出てきた個人レベルにおけるConsistencyの定義におけるAとaの使い分けをずっと理解できてませんでしたが、これは集団レベルで考えると理解がしやすくなります。

Consistencyが成立するためには、いくつかの条件が必要です。
そもそも研究を行うときに、興味のある介入をWell-definedする必要があります。 これは現実世界に実際に存在する介入を指しているのではなく、これから行おうとする研究における理想的な、研究者の頭の中にある(Hypothetical worldにおける)介入に関してです。 What ifでは'treatment of interest', 'hypothetical intervention'などと呼んでいます。
研究者の頭の中のhypothetical interventionが定まっていないと、反実仮想アウトカムも上手く定義できないことになります。 なので、Multiple version of treatmentsをなくして、ただ一つの興味のあるtreatment (Well-defined treatment)を定める必要があります。
これが第一の条件。これは確率的なブレがない、つまり実現値aで表すことができます。
では、Well-definedとは何でしょうか。想定する介入はどこまで定義すればversionがひとつに定められるでしょうか。
それはその時点での専門家のドメイン知識に依存します。Clinical setting次第でVersionの厳密さは大きく変わるので、答えはありません。その当該研究分野における妥当なラインをドメイン知識に基づいて決めていく必要があります。
例えばランニングが体重減少に与える効果を見るときに、1kmコートを時計回りに走るのと反時計回りに走るという介入が異なるversionとするべきでしょうか。現時点では、常識的に考えてもおそらく同じversionとみなして問題ないでしょう。ただし、将来的には走るときの体の傾きや方向性がなにかカロリー消費に異なる影響を与える新知見が出てくるかもしれません。なので、現時点で、という枕詞が付きます。
一方で、Consistencyの成立にはもう一つの条件が必要です。 ここで考えるのは先程の理想的な介入と異なり、現実世界(Real world)で実際に観測した介入に関することです。
現実世界で得られる介入は(Studyで想定する介入が単一だとしても)唯一ではなく、複数存在するはずです。N人の患者にはN人の患者ごとの介入のばらつきがあるということです。
”プレドニゾロン5mgを7:00の朝食後に1T PO投与”というwell-definedに思える介入を作ってStudyを進めたとしても、7:10に内服した人もいれば、水3mlで内服した人もいるかもしれません。めちゃくちゃ細かく考えると、誰一人として全く同じ介入を受ける人はいないわけです。 これらの介入のブレが、第一の条件で考えたwell-defined hypothetical interventionとどこまで同じものと見なせるでしょうか。
内服するのに水を3ml飲んだとしても10ml飲んだとしてもアウトカムに影響は与えないかもしれません。どこまでこのブレが無関係(irrelevance)なのか、というのは第一の条件と同じく、その時点でのドメイン知識に依ります。 (上記の例でも、対象患者が人なのか2kgの犬なのかでだいぶ話は変わってきそうです。)
この二つめの条件は、'treatment variation irrelevance'と呼ばれます。 理想的な介入と、現実世界での介入が同じものとみなせるか(現実世界での介入のブレはアウトカムに無関係)どうか、という話です。
なので、現実世界での介入は、N人の患者がいたら、a1, a2, …, aNというように、厳密にはN個分の介入を考えることができ、それらを合わせてA={a1, a2, …, aN}というベクトルAの確率変数と表すことができます。
この2つの条件
- 研究で想定する仮想的な介入が複数のVerisonをもたないこと (Well-defined treatment; aを定義)
- well-definedな仮想的介入と、現実世界での介入(群)Aが同じものと見なせること (treatment variation irrelevance; A=a)
が満たされるとき、Consistencyが成り立つといえます。
If A=a, then Ya=YA=Y
このConsistencyの等式は、 1.の条件は明示的には定めていませんが、暗示的にaがwell-definedであることを仮定しています。
"If A=a"の部分で、treatment variation irrelevanceが成り立つことを仮定しています。 その仮定が成り立つもとでは、
仮想的でWell-definedな介入aを受けた反実仮想アウトカムYa と、 現実世界における介入(群)Aを受けた反実仮想アウトカムYA が等しくなります。(Ya=YA)
また、観測アウトカムYは、当然現実世界における介入(群)Aを受けた反実仮想アウトカムと同じですから(Y=YA) これらの等号を合わせて、 Ya=Yが導かれます。
つまり、well-definedな介入を行った場合の反実仮想アウトカムと、実際に得られた観測アウトカムが一致する、ということになります。 反実仮想と現実のアウトカムが繋がりました。 これがConsistencyが主張しているものです。
以下のスライドは上述の説明をまとめたものです。

Clinical epidemiology the essentials- Chapter 9 treatment
大学院の輪読会でClinical epidemiology the essentialsを読んでいます。 https://www.amazon.co.jp/Clinical-Epidemiology-Grant-Fletcher-MPH/dp/1975109554
タイトル通り臨床疫学のエッセンスがコンパクトに詰まっていて、かなり勉強になります。 既に大学院授業で習ったことも多いけど、自分で再度まとめ直して発表するというのは理解の深度を上げ知識の定着に非常に効果的だと思います。
僕含めて二人のゼミ生で交互に分担し、今回はChapter9 Treatmentに関する章を担当することになりました。RCTのInterventionの関連概念の記述がかなり多く、RCT Designについても多く紙面を割いています。
なんとなく聞いたことはあったけどちゃんと学んだのは初めての概念も結構多く(Cluster randomization, N of 1 trialなど)、新鮮で面白かったですが、概説だけだったので、理解するにはRCT専門の教科書を読み込む必要がありそう。
Effectiveness in Individual Patientsというサブセクションに出てきた文章が個人的にかなりハマったというか、教科書随一の名文だと思いました。
results of valid clinical research provide a good reason to begin treating a patient, but experience with that patient is a better reason to continue or not continue.
最初何を言いたいのか分からなかったのですが、全体を読んだあと立ち返って腑に落ちました。
RCTなどの臨床研究では、特定の集団に対する平均的な効果を推定しているわけですが、それをどう臨床現場で個別の患者に当てはめ、どう活用していくか。
正しく組まれた臨床研究において、ある介入の有効性が示されたとき、その研究を根拠にして、介入を目の前の患者に適用(indication)することは合理的。 しかし、その介入を継続するべきか、やめるべきかは目の前の患者の経過(experience)を重視して考えるほうが良い。 と解釈しました。
(当たり前なのかもしれませんが)EBM偏重になりすぎるのも良くないよ、EvidenceとExperienceのバランスを考えようねという主張だと思います。
ほとんどのEvidenceは集団への平均効果を見ているに過ぎず、個別の患者への効果を見ているわけではないので、その介入結果がいくら良かったとしても、目の前の患者に同じような効果をもたらす根拠は無いわけです。 なので、その介入を選択して開始する根拠には使えても、本当にその患者に対して期待する効果をもたらしているのか、メリットがデメリットを上回っているのか、というのは臨床的な経過と患者ひとりひとりのExperienceに基づいて個別に吟味する必要があります。
"Clinical" epidemiologyならではの視点だなと思いました。 この考えを念頭に置いて、Epidemiologist かつClinicianとして仕事をしていこうと思いました。
Causal inference- What if chapter2勉強まとめ
因果推論の王道教科書Causal inference- what ifを読んでいます。 https://www.hsph.harvard.edu/miguel-hernan/wp-content/uploads/sites/1268/2024/04/hernanrobins_WhatIf_26apr24.pdf
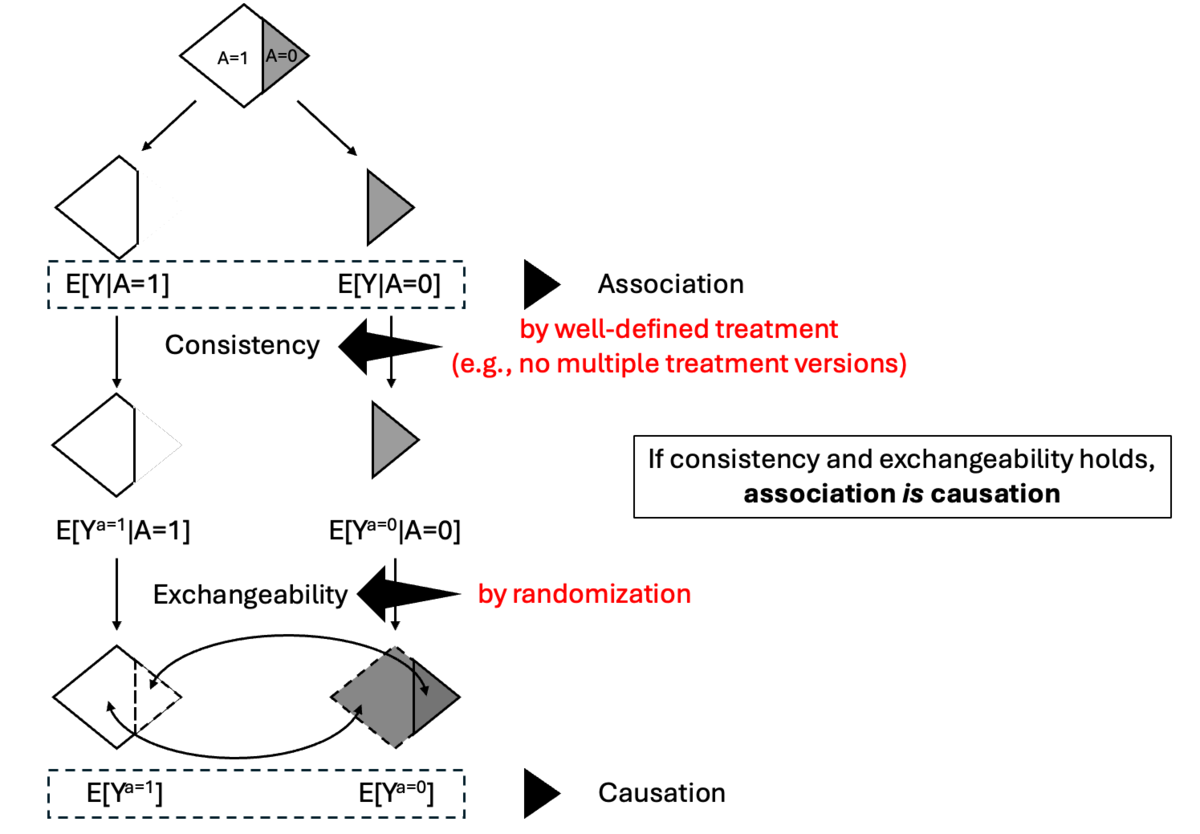
月に1chapterずつゆっくりやっていますが、Chapter2まできて、association is causationとなる要件の本質がわかってきた(気がする)ので頭の整理のために図解してみました。
Causationを推論するために必要な重要な仮定はなにか、RCTがなぜ因果推論の強い手法になっているのかというのが理解できるようになりました。
RCTのRisk of bias assessmentにおいてRandomizationが正しく実施されているかどうかを重点的に評価する理由がわかったし、そもそも治療の定義をうまくできているのか(well-definedか否か)といった研究計画の入念な検討が最重要になってきます。
やはりWhat ifはいい本です。
<論文感想>ベナゼプリル+スピロノラクトンの併用がMMVD犬の心臓アウトカムの抑制効果をもたらすか評価したRCT(BESST study)
BNZ+SはBNZ単独使用に比べてMMVD stageCの犬のCardiac endpoint到達率を下げるか?
Coffman, M. et al. Clinical efficacy of a benazepril and spironolactone combination in dogs with congestive heart failure due to myxomatous mitral valve disease: The BEnazepril Spironolactone STudy (BESST). J. Vet. Intern. Med. 35, 1673–1687 (2021).
https://onlinelibrary.wiley.com/doi/10.1111/jvim.16155
- ACE阻害薬はRAAS系をターゲットとした心臓治療薬であり、医学分野では特にHFrEF患者で有効性が示されている
- 犬のMMVDに対する有効性はControversialであり、どのStageでどのアウトカムを評価するかにより結果は異なっている
- RAAS系抑制を行うと、代償的経路の活性化が生じ、ACE阻害薬の効果が低下するアルドステロンブレイクスルーという現象が知られている。
- ACE阻害薬に加えてアルドステロン受容体の拮抗薬であるスピロノラクトンを併用することで、アルドステロンブレイクスルーを対処する事ができる
- 本研究ではACE阻害薬(ベナゼプリル; BNZ)とスピロノラクトン(S)の併用がBNZ単独よりもMMVD犬のCHFコントロールの観点で優位性があることを検証する
方法
フランスの製薬会社Ceva Sante Animale(本研究で使用されたスピロノラクトン, CARDALISの開発元)が資金提供&共著者となっている
PECOS:
P詳細
exclusion: 妊娠、繁殖中、授乳中、非心原性失神、先天性心疾患、重度併発症、10日以前にACEi以外の心臓薬を使用、Day0時点で利尿薬、ACEi, Digoxin, diltiazem以外の心臓薬を使用
→さらにSafety, efficacy, modified efficacy sampleに段階的に除外基準を設けて各Sampleでアウトカムを評価し、Primary outcomeはEfficacy/modified efficacy sampleのoutcomeで効果を判定
- Safety sample: 解析対象集団の内、”少なくとも一回”投薬を受けた患者; 有害事象評価が主な目的
- Efficacy sample: Safety sampleのうち、Protocolを大きく逸脱した患者を除外し、マイナーな他の除外を経たSample
除外理由
- 研究開始7日以内にcardiac endpoint到達した患者
- 非心原性イベント発生した患者(AE、怪我、非心原性死亡/安楽死)
- 投薬量のミス、追跡失敗、何らかの実施不備の発生
- オーナーが参加拒否を表明
- 参加後に除外基準を満たしていることが発覚
- 治療群への割当が2頭以下となった施設
Modified Efficacy sample: Efficacy sampleのうち、FurosemideのDose up(>6mg/kg/d at day0 or 8mg/kg/d after day0)を行った患者を除外
結果
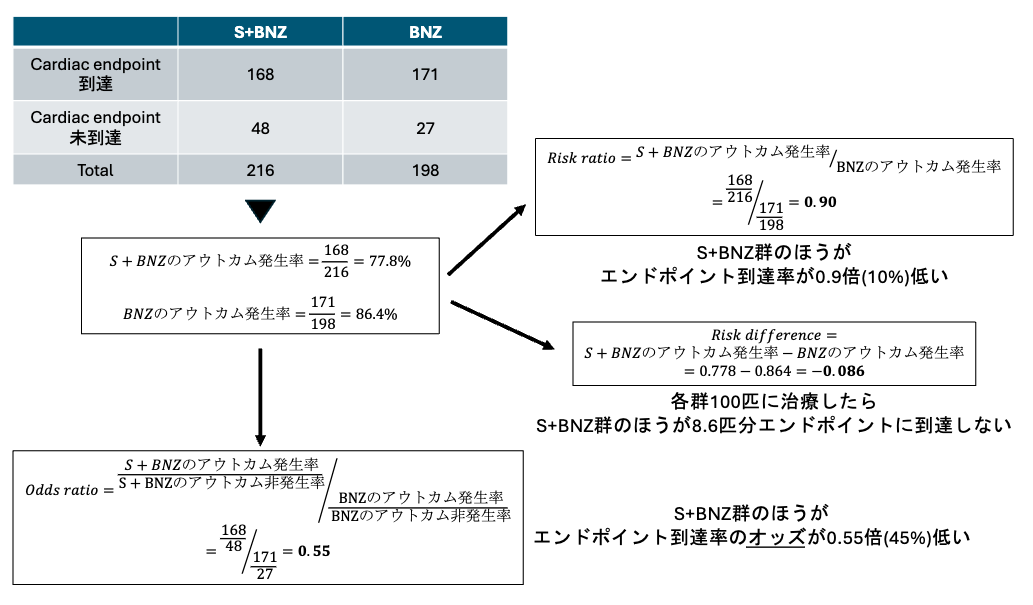
- Efficacy sampleにおいて、Primary outcomeであるCardiac endpointへの1年到達率は、S+BNZ群でBNZ群より少ない(77.8% vs 86.4%)
- 各時点におけるCaridac endpointの到達率もS+BNZ群のほうがBNZ群より少ない
- Time-to-analysisにおいてもS+BNZ群はBNZ群よりCaridac endpointの到達速度は低い(MST 105 days vs 69 days)
- 有害事象の発生に関しては、嘔、腎機能低下、肝腫大はS+BNZ群のほうがやや多いが、尿失禁はBNZ群のほうが多い
感想
- 研究デザインは非常に練られている。
- 必要症例数の多さや、組入基準、除外基準の細かさ、細部のプロトコールまで記載されているところに、気合を感じる。製薬会社との共同研究であるが、やはり臨床研究は製薬会社が強い。
- Primary outcome, secondary outcomeの解析を含めて、S+BNZでBNZに比べて有効性が高いという結論の方向性には同意する。
- しかし、Primary outcomeの解析とその効果量の大きさの示し方に疑問が残る。必要症例数の設計は、2群の治療失敗に関するリスク差(RD)=15%(60% vs 45%)を検出したい最小の効果量として設定し、Fisherの正確確率検定で算出している。それそのものは何も問題ないが、実際の結果(Fig3)では、2群間のリスク差が8.6%であり、示したい最小の効果量に達していない。また、メインの結果をOdds ratio(OR)で示し、その効果量が0.56とS+BNZ群に有効であると示しているが、Cohortを用いた解析で、有効性をリスク比(RR)やRDで示さず、ORで示すところに非常に強い恣意性とミスリーディングの意図を感じる
- ORは因果的な解釈が難しく、各群のイベント発生のOddsの比としてしか解釈できない(今回なら、S+BNZ群のほうがエンドポイント到達率のオッズが0.55倍(45%)低い、という解釈になる)。さらに、一般的にORはRRよりも大きな効果量として表される事が多く、RRとORの効果量には乖離が生じる。イベント発生率が低い(3-5%など)状況であればORはRRに近似できるが、今回はイベント発生率が両群ともに15-20%程度であり、先行研究からも比較的高い発生率になることは想定できているため(本文中でも引用されている文献をみても10-20%と想定される)、ORで結果を表現する妥当性が無いと思われる。今回の結果をRRで計算し直すとRR=0.9(S+BNZ群のほうがエンドポイント到達率が0.9倍(10%)低い)となり、論文中での結果(OR=0.55)と効果量に大きな違いがあることがわかる。
- メインの解析結果をあたかも大きな効果量を持つかのように表示してミスリーディングを狙っているように受け取られても仕方ないのでは無いかと思う。あまりRCTでORをメインに表示することはないし、Fig3ではBar chartでエンドポイント未到達率を示しているにも関わらず、説明文ではORの検定結果で有意差の説明を書き、有意差マークをグラフに付与しているところも、RDに有意差があるかのような書き方にしているところに恣意的な表現を感じる。
- 全体的なデザインはとても丁寧で参考になり、結果の方向性にも納得がいっている分、メインの結果をこのような誇張した表現で示すところが残念。製薬会社主導の臨床研究はやはりすこし穿った見方をしたほうがいいのかもしれない。