予測モデルの性能を評価するときは、データの過学習(Overfitting)を考慮する必要がある。
モデル構築で使用したデータに過剰に最適化され、新規データの予測性能が低下する問題が生じるため。
過学習は予測性能を過剰に見積もるバイアスの原因なので、さまざまな方法で過学習の程度を評価し、バイアスを補正した形で予測性能を見る必要がある。
その方法として代表的にはCross Validation(CV)とBootstrapがある。
CV
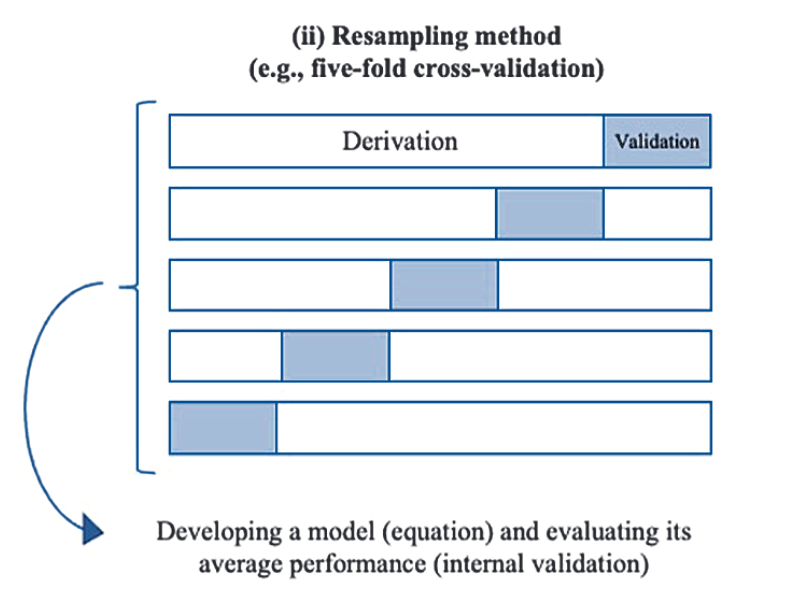
CVでは、まずデータをモデル構築用のデータと、性能検証用のデータに分割する。
モデル構築用データを元に作成した予測モデルを使い、モデル構築には使用しなかった性能検証用のデータを代入して予測性能を評価する方法。
当然、一回だとデータの分割の仕方によって大きく影響を受けるので、分割領域を次々変えて多数のモデル構築→性能検証を繰り返し、最後に得られた予測指標の平均値を算出する。
欠点は、データを分割しているので、アウトカム発生数が少ないときには予測因子の投入数が制限されることなど。
以下の模式図が分かりやすい。
Bootstrap
Bootstrap samplingは、あるオリジナル集団から、重複を許してランダムにサンプリングを行い、オリジナルデータと同数の新しいリサンプリング集団を作出すること。
これを何度も繰り返すことで、オリジナル集団と同数の集団を多数作成できる。
このリサンプリング集団を用いて、予測モデルを作成する。このときリサンプリング回数(B)の数だけ予測モデルが作成されることになる。
構築した予測モデルで、元のリサンプリング集団における予測指標(AUCなど)を算出すると、B個分のAUCが生成される(AUC1_i; i:1~B)。このAUCは当然、同じデータを使ってモデル構築とモデル性能評価も行っているので、過学習されていると考えることができる。
どの程度過学習されたのかを見るために、各予測モデルを使ってオリジナル集団における予測指標を算出する。ここでも予測モデルの数だけAUCが得られる(AUC2_i; i:1~B)ことになる。AUC2は、少なくともAUC1よりは過学習の影響を受けていないはずだから、AUC1とAUC2の差が過学習の程度(optimism)であり、推定値のバイアス分になる。
optimism=AUC1-AUC2もB個分存在するので、平均化したものを算出する。
最後に、オリジナル集団を使って作成した予測モデルを、オリジナル集団に当てはめたときのAUCを算出し、先程のoptimismの平均値を引いたものが、bias corrected AUC estimationになる。
CVではモデル構築に使うデータと性能評価のデータを分けることで過学習に対処していたが、bootstrapではオリジナル集団のサンプルサイズを保ちつつ、過学習の程度を定量化し、過学習によるバイアスを補正することで対処している点が異なるアプローチということになる。
Bootstrapの方法では、AUC2はAUC1に比べて過学習のバイアスは少ないが過学習がゼロになっているわけではないので、得られたoptimismだけでバイアスの補正は十分なのか?という部分が気になる。つまり、bootstrapではオリジナル集団から重複を許したリサンプリングなので、モデル構築で使用したデータと性能評価で使用したデータの構成要素は同じであり、完全に別個のデータではない。AUC2に残っている過学習バイアスを取り除く方法は無いのだろうか。宿題。
CVをRで実装してみる
#k-fold CV k <-5 AUC_CV <-data.frame(matrix(ncol=2,nrow=k)) form<-as.formula( DAY30 ~ rcs(AGE, 4) + DIA + HYP + HRT + ANT + PMI + FAM + TTR + rcs(WEI, 4) + AGE + ANT*AGE + DIA*HYP + HYP*FAM + HRT*ANT) #Randomly shuffle the data data2r<-data2[sample(nrow(data2)),] #Create k equally size folds folds <- cut(seq(1,nrow(data2r)),breaks=k,labels=FALSE) #Perform k fold cross validation for(i in 1:k){ #Segment data2r by fold using the which() function testIndexes <- which(folds==i,arr.ind=TRUE) testData <- data2r[testIndexes, ] trainData <- data2r[-testIndexes, ] fit1<-glm(formula = form, family = binomial(link = "logit"), data = trainData) testData$fitted<-predict(fit1,testData,type="response") ROC <- roc(testData$DAY30, testData$fitted) AUC_CV[i,2] <- ROC$auc AUC_CV[i,1] <- i #print(paste(i,"th cross-validation iteration is completed.", sep="")) } names(AUC_CV)[2] <- "AUC_cv" names(AUC_CV)[1] <- "k" print(summary(AUC_CV$AUC_cv))
CVによるAUCは平均0.8269
![]()
Bootstrap samplingをRで実装
B<-100 #number of resampling N<-dim(data2)[1] #data2のdimentionを返す→2973行x33列→そのうち一番目(2973)を取得しNとする AUC.i1<-AUC.i2<-numeric(B) for(i in 1:B){ #bootstrap random sampling bs.i<-sample(1:N,N,replace=TRUE) #重複を許して1~2973までの数を2973回サンプリングする #bootstrap samplingに基づき、data2から集団を再構成 →data2.iとする data2.i<-data2[bs.i,] #bootstrapしたデータセットごとで回帰モデル構築→各bootstrap dataからリスク予測確率の算出→data2.1のprob_1列に格納 gm1.i<-glm(formula = form, family = binomial(link = "logit"), data = data2.i) data2.i$prob_1<-predict(gm1.i,data2.i,type="response") #AUCの算出;Bootstrap回数(B=100)分のAUCを算出して結果を格納 AUC.i1[i]<-roc(DAY30~prob_1,data=data2.i)$auc #bootstrapで作成した各回帰モデルを使って、オリジナルデータ(data2)からリスク予測確率を算出→data2のprob_2列に格納;AUC算出 data2$prob_2<-predict(gm1.i,data2,type="response") AUC.i2[i]<-roc(DAY30~prob_2,data=data2)$auc #ここで得られるAUCはbootstrap glmを用いてoriginal data2に外挿したときのAUC #print(paste(i,"th bootstrap iteration is completed.",sep="")) } #optimism(過学習によるバイアス) opt1<-AUC.i1-AUC.i2 summary(opt1) hist(opt1) lam1<-mean(opt1) #estimate of the optimism #original dataを使って、originalのstepwise modelからorignialのAUCを算出→AUC1 gm1<-glm(formula = form, family = binomial(link = "logit"), data = data2) data2$prob1<-predict(gm1,data2,type="response") AUC1<-roc(DAY30~prob1,data=data2)$auc #original dataにおけるstepwise model(original model)のAUC AUC.c1<-AUC1-lam1 #bias corrected AUC estimate AUC.c1
bias corrected AUC estimateは0.8292でありcross validationのAUC(0.8269)とほぼ一致!
CVとBootstrapでぜんぜん違う過学習に対するアプローチを取っているけども、ほぼ同じような推定値になっているのはすごい。
実際に手を動かしてみるとCVやBootstrapの概念を深く理解できるようになったと思う。やはり論文や教科書を読むだけじゃなくて自分でやってみるのが一番勉強になる。